
Current REU Projects
In each research project, students will work closely with two or more members of our staff. The projects will be in a wide variety of areas, including but not limitied to various High Performance Computing (HPC) & Research (RC) topics:
- AI & machine learning
- Data analytics
- Dasboards & visualization
- HPC software deployment & solutions
- Interface design & user experience
- HPC benchmarking & workflow scaling
- Scientific & eduacational applications solutions
- Containerization
- and more!
Summer 2026 Projects

Project #1: Exploring Quantum AI with Anvil
Step into the future of computing with this hands-on project that connects Quantum Computing, Artificial Intelligence (AI), and High-Performance Computing (HPC)! As part of the Anvil REU project team, you'll use Open OnDemand to create interactive tools and learning materials that make cutting-edge Quantum Computing and AI more accessible for students, researchers, and professionals in Science, Engineering, and Medicine (SEM). You'll explore how classical and quantum computing can work together, through quantum simulation, machine learning, and optimization, to tackle some of the biggest challenges in modern research. A working prototype is expected to debut in Spring 2026 to support the Quantum Computing for Materials Science and Chemistry (QC4MC) Summer School. Your contributions will help shape a larger NSF CyberTraining project proposal (QAI4SEM), expanding the impact of Quantum AI education and research nationwide. This is an exciting opportunity to: (1) Build real tools that advance Quantum AI learning and research, (2) collaborate with experts in HPC, AI, and Quantum Computing, and (3) gain experience that bridges computing, science, and innovation.
Requirements: Basic experience with Linux command-line environments, familiarity with Python programming, exposure to Open OnDemand and Slurm workload management, understanding of Git/GitHub for version control and collaboration, foundational knowledge of Artificial Intelligence (AI) and Machine Learning (ML) concepts, and introductory understanding or interest in Quantum Computing.
Prior coursework or hands-on experience in any of these areas is helpful, but curiosity and a willingness to learn are just as important. If there is no direct experience the ability to successfully complete a relevant course, for example, Coursera's Applied Machine Learning in Python and IBM Learn Quantum Computing, before the start of the REU program is required.
Pre-REU Trainings:

Project #2: SciAgents: AI Agents for Scientific Discovery and Reproducibility
Imagine a world where science moves faster, and smarter, thanks to AI working alongside researchers. That's the vision behind SciAgents, a next-generation system of AI-powered agents designed to help scientists discover, test, and validate new ideas more efficiently. As part of this project, you'll help build an integrated network of specialized AI agents that collaborate to perform end-to-end research workflows. Each agent has a unique role: (1) Literature Agent – analyzes research papers to extract key experimental details, (2) Data Agent – discovers, organizes, and preprocesses scientific datasets, (3) Experiment Agent – designs and runs computational experiments, and (4) Synthesis Agent – interprets results and generates new scientific insights. To take it even further, you'll help develop an Interactive Reproducibility Checker, a tool that reads a paper's methods section and tries to recreate the experiment automatically. It flags missing information like software versions, hyperparameters, or unclear data splits, benchmarking each workflow against established standards such as the ACM Artifact Review, FAIR Principles, and the ML Reproducibility Checklist. By bringing together discovery, experimentation, and validation in one intelligent system, SciAgents aims to revolutionize how scientific research is conducted and verified. This project is perfect for students who want to: Work at the intersection of AI, data science, and research innovation, contribute to tools that promote transparency and reproducibility in science, and gain hands-on experience building multi-agent systems with real-world impact.
Requirements: Familiarity with foundational data analysis and AI/ML methods and frameworks, basic understanding of Python programming, exposure to LangChain or LlamaIndex (or a willingness to learn), understanding of APIs (e.g., semantic search, literature mining) and working with JSON schemas, and experience using Git/GitHub for version control and collaboration.
Prior experience with large language models (LLMs) is a plus, but not required. Candidates without direct LLM experience may still qualify if they demonstrate strong foundational skills or successfully complete a relevant course or documentation, for example, Coursera's Applied Machine Learning in Python or LangChain, before the start of the REU program.
Pre-REU Trainings:

Project #3: Elastic Cloud Scheduling for Anvil
Help push the limits of high-performance computing by making GPU use more efficient and flexible on the Anvil supercomputer. Currently, Anvil can convert entire compute nodes into Kubernetes workloads, but GPU nodes, often equipped with multiple GPUs, must be allocated as a whole. In this project, you'll develop a fine-grained scheduling system that enables single-GPU allocation across heterogeneous compute environments and multiple Kubernetes clusters. Your work will help researchers use powerful GPUs more effectively, reducing waste and improving access for AI, machine learning, and data-intensive applications. This project is perfect for students interested in HPC, cloud computing, or systems engineering who want hands-on experience developing real solutions for large-scale research computing.
Requirements: Familiarity with Linux environments and basic Bash scripting, experience with a scripting language such as Python, understanding of Kubernetes concepts and configuration, exposure to Crossplane, Interlink, and DGX SPARKS (or a willingness to learn), knowledge of Slurm workload management and HPC job scheduling, and experience using Git/GitHub for version control and collaboration.
Prior experience with container orchestration or cloud-native infrastructure is helpful but not required; curiosity and a desire to learn new technologies are key. Candidates without direct experience may still qualify if they demonstrate strong foundational skills or successfully complete a relevant course or documentation, for example, Codecademy – Learn Python, before the start of the REU program.
Students must be able to complete the following trainings prior to the start of the REU program:

Project #4: Building a Scalable Data Federation for Anvil Using the Pelican Platform
Unlock the power of data federation and distributed computing in this hands-on project using the Pelican Platform. As an REU student, you'll deploy infrastructure to federate data access on Anvil, providing a unified endpoint to scientific data hosted across Anvil's multiple petabyte (PB) scale distributed storage systems. This project uses Pelican as an abstraction layer to connect multiple, technologically diverse storage resources as unified data origins, enabling seamless access and integration across diverse computing environments. Leveraging Pelican's infrastructure for data distribution and caching, you'll develop example workflows and container-based analysis pipelines that are generalizable and reproducible to support the usage of the Anvil data fabric for AI and scientific computing. This project is ideal for students interested in systems engineering, data science, distributed computing, and workflow automation, especially those eager to build tools that make large-scale, data-driven research more efficient, connected, and reproducible.
Requirements: Basic understanding of Linux or UNIX environments, including basic system administration tasks (e.g., file permissions, process management, software installation), experience with at least one scripting or programming language (e.g., Python, Bash), familiarity with version control tools such as Git/GitHub, interest in data management, storage systems, or high-performance computing (HPC), interest in or exposure to the Pelican platform, and strong attention to documentation and reproducibility practices.
Candidates without direct experience may still qualify if they demonstrate strong foundational skills or successfully complete a relevant course or documentation, for example, Google's Python Class or Learn Python and an understanding of the Pelican Platform, before the start of the REU program.
Students must be able to complete the following trainings prior to the start of the REU program:
Past REU Projects
Summer 2025

Project #1: Building a data warehouse to store and manage logs from data center and compute systems, integrating data sources and creating visual dashboards.
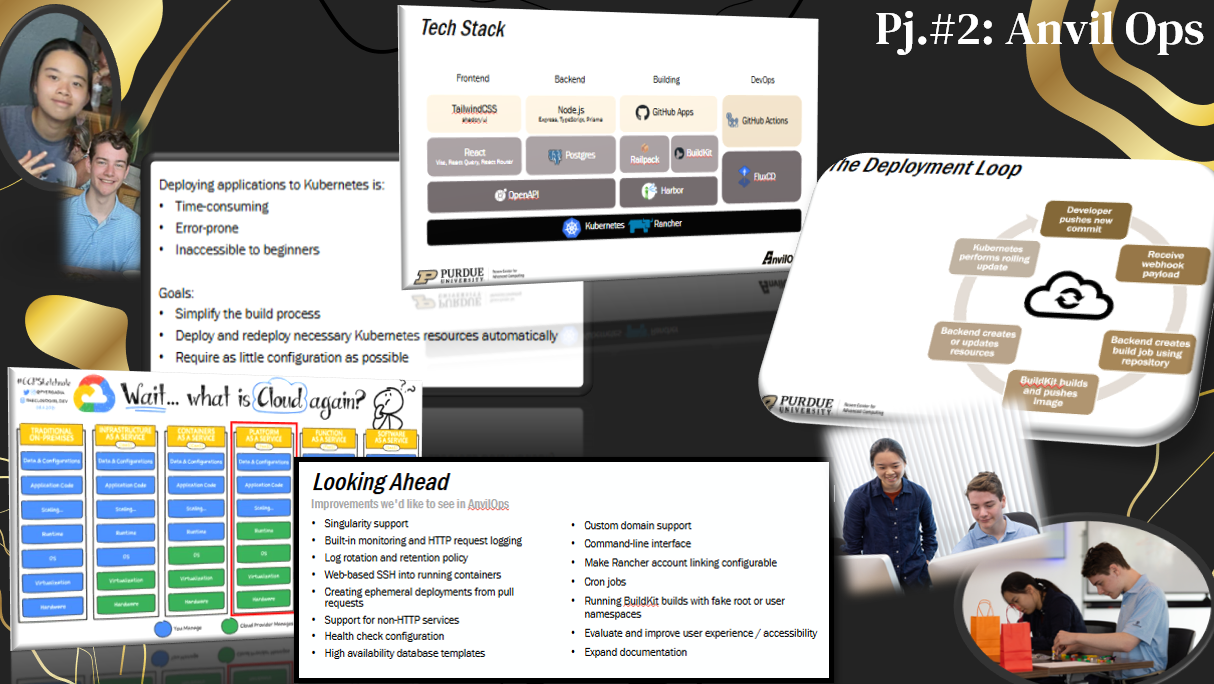
Project #2: Developing a dynamic web interface for building and deploying container workloads on Anvil' Features include Dockerfile/Singularity uploads, Git repository integration, and streamlined container management.

Project #3: Creating user-friendly workflow templates for essential bioinformatics tasks including RNA-seq, variant calling, and genome assembly. Templates include optimized SLURM job scripts and organized file structures for efficient resource utilization.
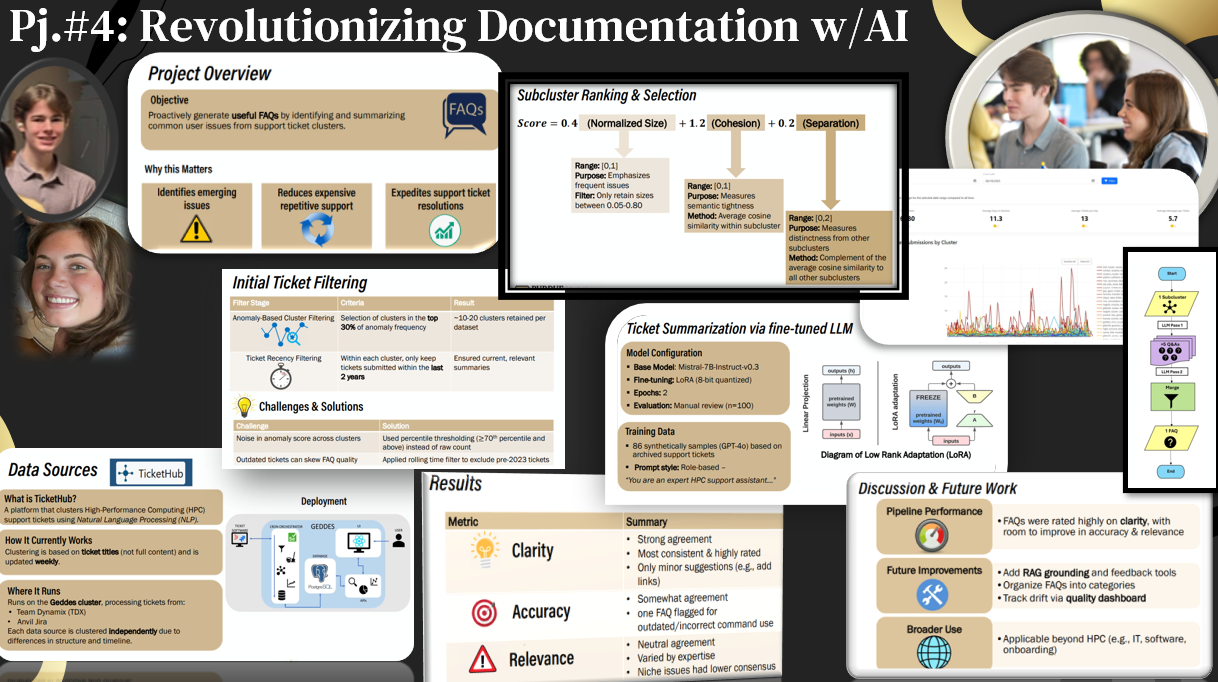
Project #4: Enhancing TicketHub to automatically generate FAQs and standard responses using NLP and large language models. Extracting key information from systems, past support requests, and documentation to streamline technical support processes.
Summer 2024

Project #1: Streamlined Software: Automating user-requested software deployment on Anvil using agile technologies
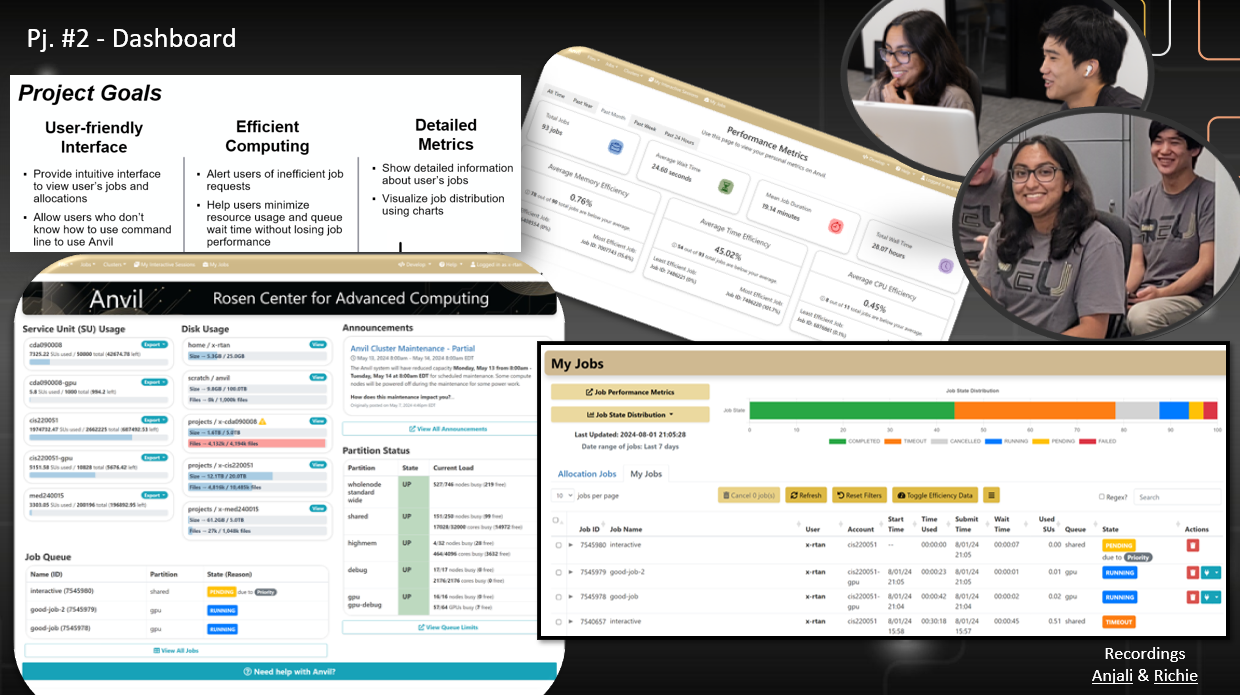
Project #2: Unlocking the Impact of Data: The Power of the Dashboard
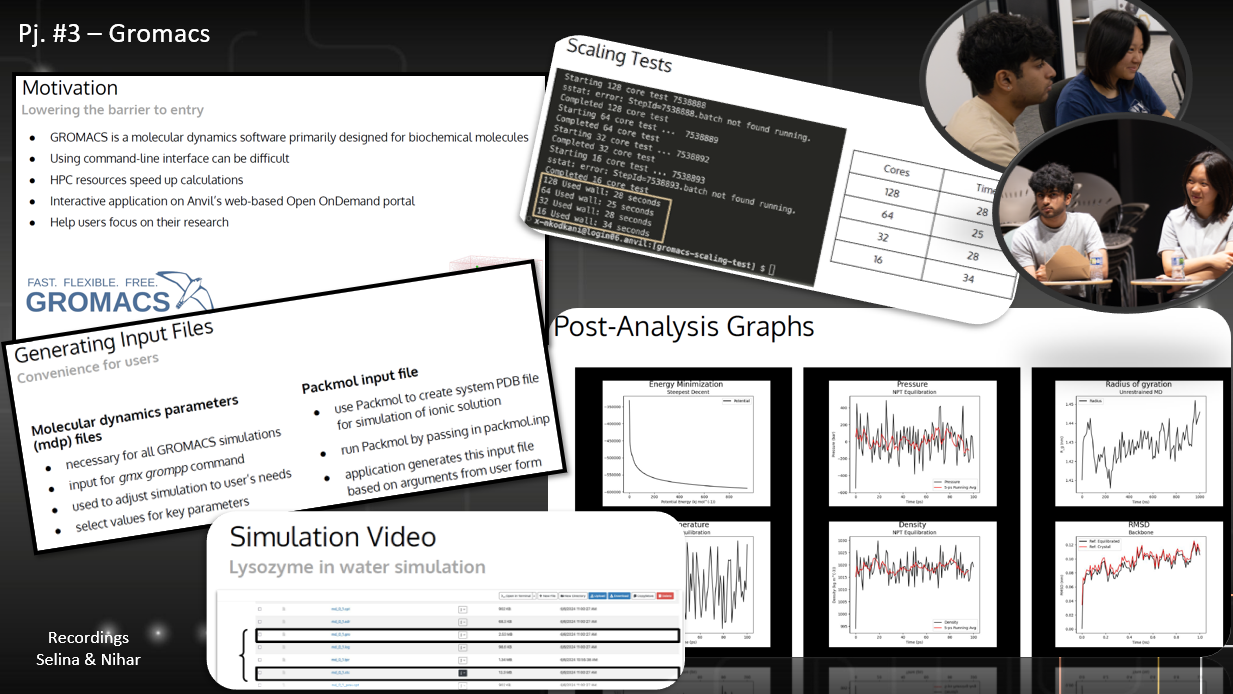
Project #3: Gromacs Gateway: Creating User-friendly Molecular Simulations Online
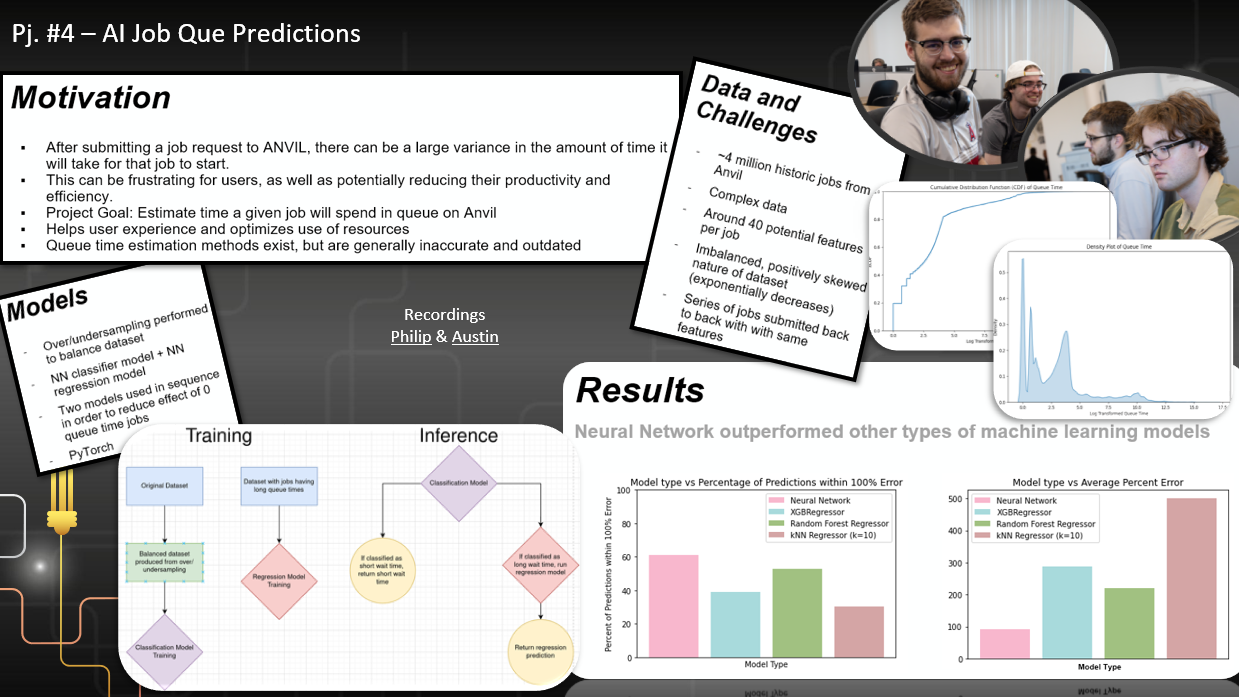
Project #4: AI-Powered Operational Data Analytics: Enhancing User Experience on Anvil
Summer 2023
Projects focused on a wide variety of areas, including data analytics, high performance computing, DevOps, and containerization.

Project #1: Integrate the XALT job-level usage activity monitoring tool into XDMoD reporting for deeper analysis of workloads.
.png)
Project #2: Implement direct cloud burst from Anvil to Azure for HPC and accelerator workloads based on the work with Microsoft in 2022.
.png)
Project #3: Connect the Anvil composable subsystem’s Rancher management platform to Azure Kubernetes Service to support elastic-scaling of workloads for science gateway applications.
.png)
Project #4: Develop deployment solutions for the Jupyter notebook interactive computing platform on Anvil’s composable subsystem for education and training activities.
Summer 2022
Projects focused on improving data collection and reporting of the Anvil cluster to ensure quality of service, effective system utilization, and performance.
While benchmarking compute and storage performance, students:
- Learned concepts surrounding benchmarking of HPC systems, including HPL, HPCG, STREAM, and IO500
- Measured performance of Anvil's compute nodes, GPU nodes, scratch, project, and BeeOND filesystems
- Established baselines for system performance for a continuous measurement framework
To improve data collection and reporting, students:
- Configured multiple modules on Anvil's XDMoD instance and improved data collection and reporting of system metrics
- PCP, SUPREMM
- Open OnDemand data collection
- Continuous measurement framework via Application Kernels
For system environmental measurements, students:
- Created monitoring of Anvil's power consumption at the node and rack levels using Prometheus and Grafana
Fall 2022
Enhance Anvil's cybersecurity posture, utilizing an NSF CICI-funded intrusion detection system to monitor aspects of Anvil's network and enable visualization-driven insights into network traffic and cybersecurity alerts. Students helped with:
- Visualization of network traffic trends on Anvil and Purdue networks
- Dashboard development based on Zeek IDS protocol logs (TCD, UDP, SSH, HTTP)
- Port scanning
- Per-host traffic visualization
Nondiscrimination Policy Statement
Purdue University prohibits discrimination against any member of the University community on the basis of race, religion, color, sex, age, national origin or ancestry, genetic information, marital status, parental status, sexual orientation, gender identity and expression, disability, or status as a veteran. The University will conduct its programs, services and activities consistent with applicable federal, state and local laws, regulations and orders and in conformance with the procedures and limitations as set forth in Purdue’s Equal Opportunity, Equal Access and Affirmative Action policy which provides specific contractual rights and remedies. Additionally, the University promotes the full realization of equal employment opportunity for women, minorities, persons with disabilities and veterans through its affirmative action program. View a more complete statement of Purdue's policies of equal access and equal opportunity. If you have any questions or concerns regarding these policies, please contact the Office of the Vice President for Ethics and Compliance at vpec@purdue.edu or 765-494-5830.
Anvil is supported by the National Science Foundation under Grant No. 2005632.